Layerwise Ablations on Transformers Show Funky Things
Epistemic Status: Confusion
Each layer of a Transformer -- from the 0th to the last -- takes a block of numbers and adds some residual information to it. So each layer works something like x = f(x) + x where f is the layer.
This means that, when we drop some layer, and instead simply pass-through x the performance of the Transformer might not change very much.
Let's try the experiment!
EleutherAI's Pythia is a great dataset that lets us examine how the importance of each layer changes, over the course of training. The Pythia project trained a bunch of different models of different sizes, and then saved the weights of those models at a bunch of steps.
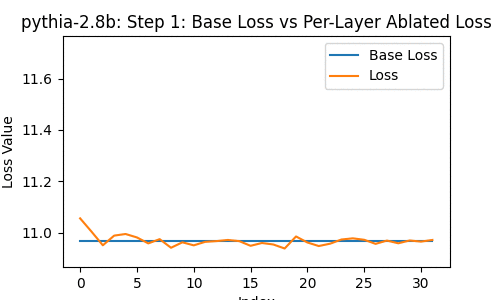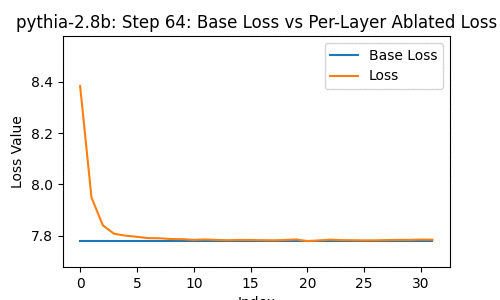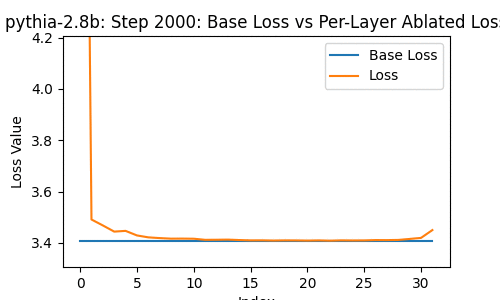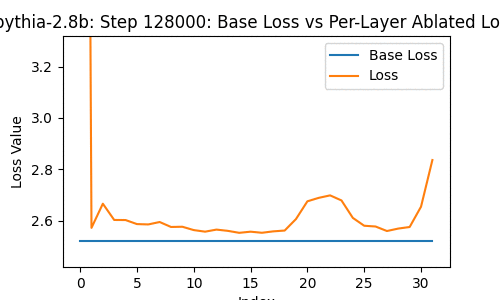
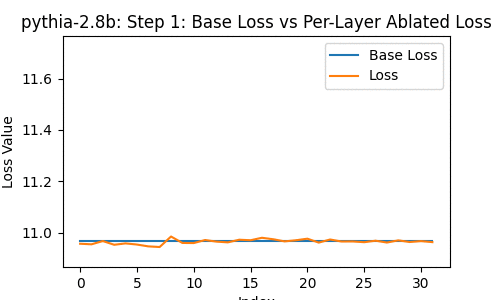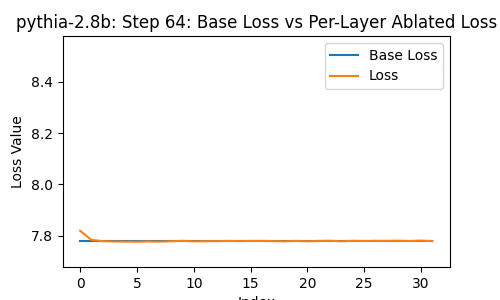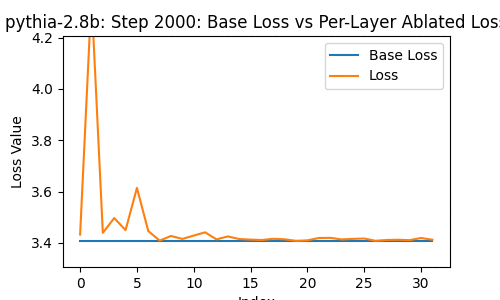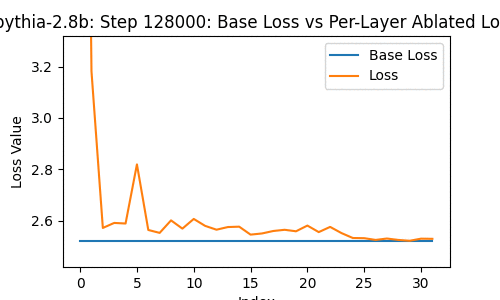
Let's take a look at the loss of the 2.8-billion parameter transformer changes, when you drop some particular layer -- over the course of the model's whole training, at the 1st, 2nd, 4th, 8th, and so on steps of training.
In the following, the blue line shows the loss of the network with no layer removed; the orange line shows the loss with some layer from 0 to the last removed.
Per-Layer Ablations Over the Course of Training:
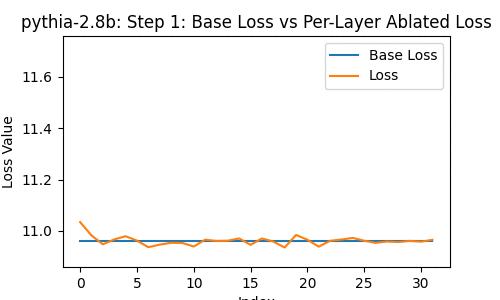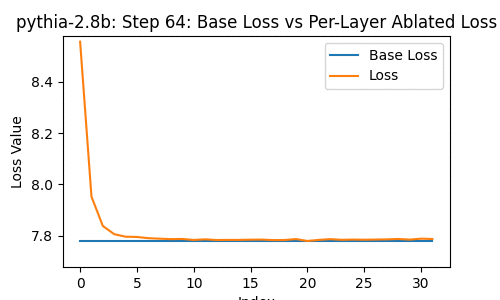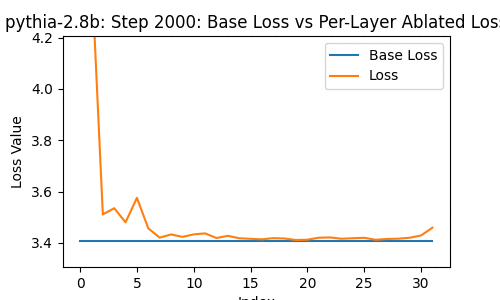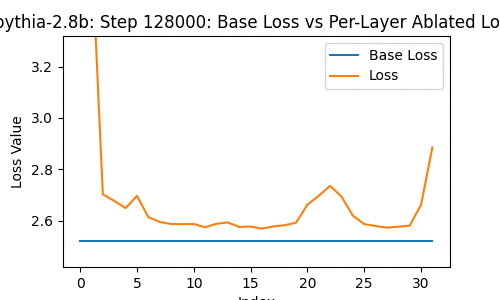
A few things instantly stand out. The top few and bottom few layers are clearly the most important, from ~1000 steps onwards.
I think this is the kind of thing I would have guessed in advance... probably. The first and last layers are, obviously, the only place you could get knowledge and facts that either (1) influence all the rest of the model or (2) get information from all of the rest of the model. So it makes sense that a kind of pride-of-place would belong to them. This also seems to be true in other non-Pythia models that I've looked at.
Similarly, it makes sense (I think?) for middle layers to be clearly much less important.
But this goes further than I expected -- there are moments during the training where dropping a middle layer in some cases actually decreases the loss!
Take a look at this frame:
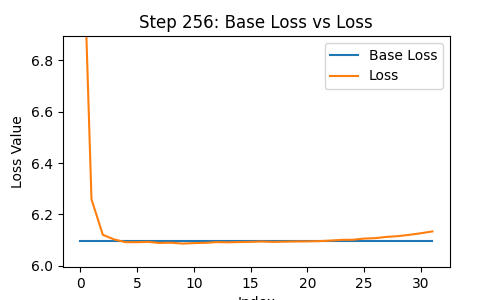
The effect is tiny, but it nevertheless exists.
What's also interesting, though, is the development of a weird tumorous 'important' location 3/4ths of the way through the model relatively late in training. I'm not sure what to make of it.
-
One thing funky about it, is that it suggests that layers being close to each other might actually matter a lot? That, despite the residual connections, there's actual significance in not being too far-removed from another layer.
-
Or maybe that this particular location matters?
Each layer in a transformer consists of an MLP and an attention layer. So you can also just remove the MLP layer.
MLP Ablations
Or just the attention part.
Attention Ablations
I'm not sure what to make of a lot of this.
It's funky that attention just looks like it... doesn't matter that much later on? The contribution it makes just gets smaller and smaller deeper and deeper and deeper in.
Just End-of-Training
Note that other transformers don't always look like this! Let's look at what some transformers look like at the end of their training:
Pythia + GPT-Neox20b
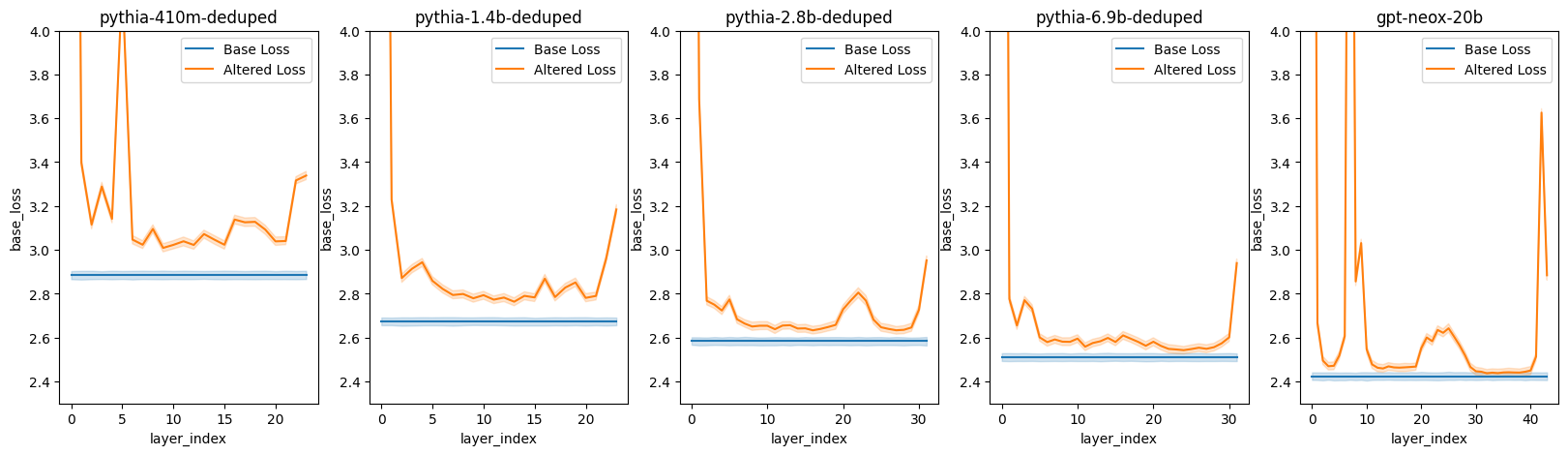
GPT-Neox is the crazy one here -- he has two sections that look like they are massively more important.
But -- not every Transformer even has such sections:
Here's Falcon 40b, another mode:
Falcon
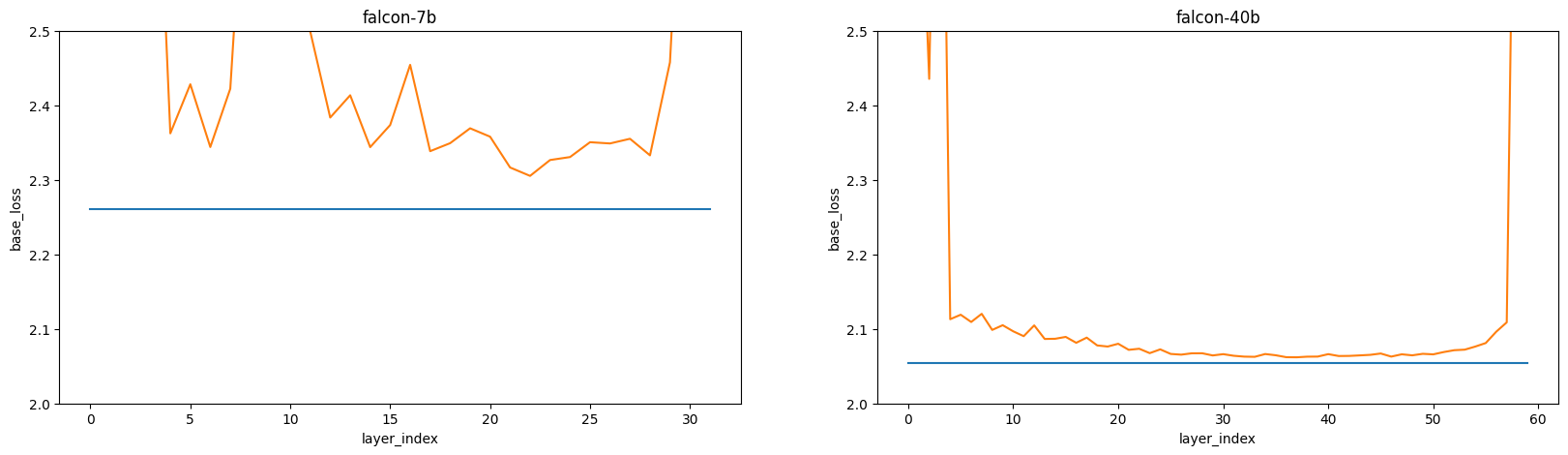
The 40b here doesn't have the weird wrinkles, and instead looks... more like what I'd naively expect? The first and last layers look kinda the same, and we have a U-shaped layer between them.
Amyhow, I don't know why Transformers learn like this in some cases and not in others. What I'm curious about:
- When spikes appear and we get more "important" layers, what's going on there?
- Could we figure out why many layers don't matter, and train more efficiently with this knowledge?
- Does the importance of layer depend on fine details of the Transformer, or will this kind of thing also appear, for instance, in state-space models?
- Have I wasted my time making these graphs?