More Evidence For Softplus Gated Attention
Gated Attention Improved by Using Softplus Rather than Sigmoid
I earlier posted about how softplus gated attention seems to improve very notably over sigmoid gated attention, which itself is an improvement over standard attention.
I have expanded my experiments to larger models, and conducted further ablations.
Softplus gated attention continues to uniformly do better than sigmoid gated attention in pretty much any realistic scenario.
Although the degree to which it improves varies at different scales, at large scales softplus seems to improve over sigmoid by more than sigmoid improves over plain attention.
Confirmation at Larger Scale
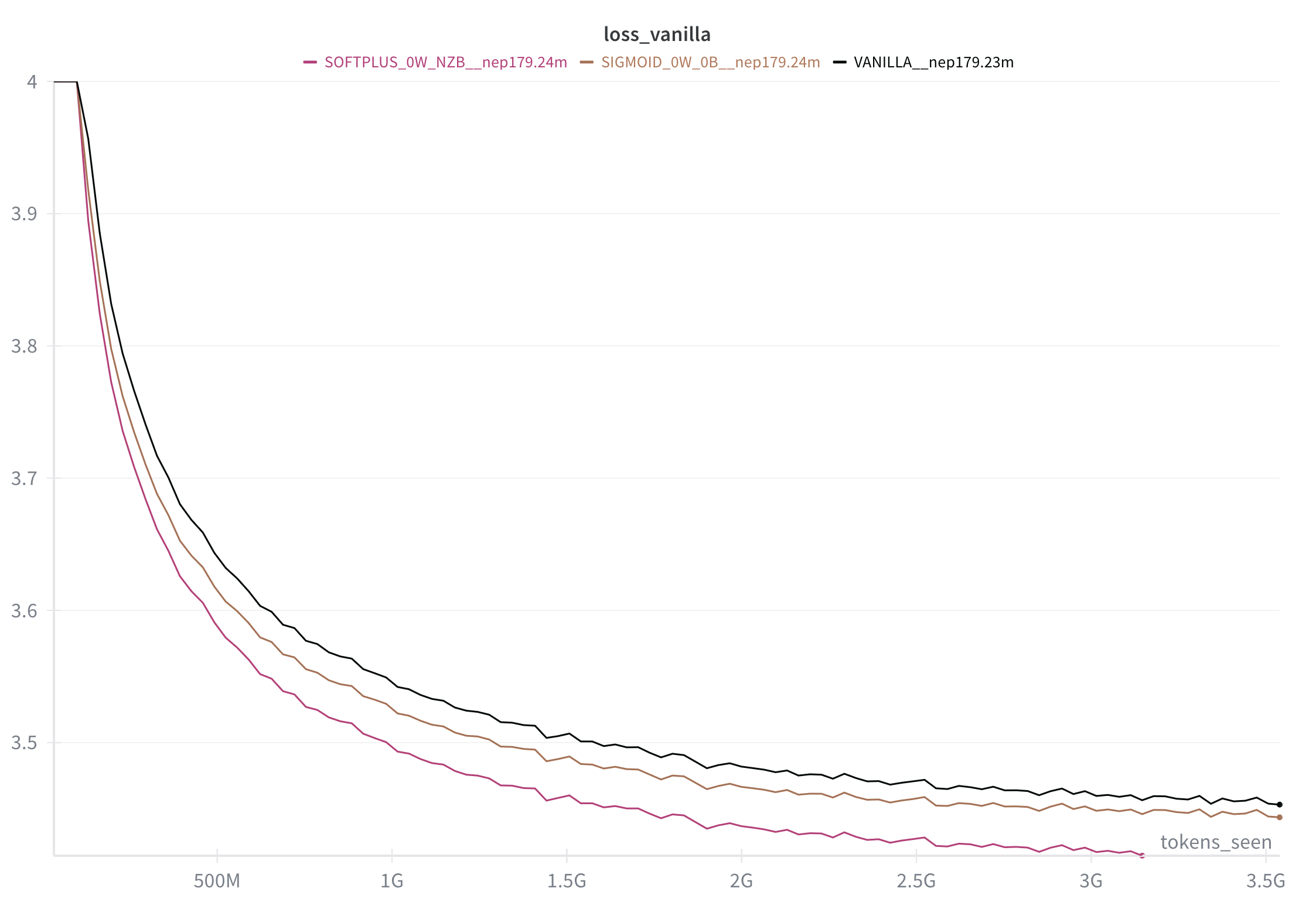
Here's what Vanilla vs. Sigmoid Gates Attention vs. Softplus Gated Attention looks like for 170m active parameters @ 3.5 billion tokens. (Note this uses a linear LR decay that's almost certainly not optimal, particularly for the last 30% of training.)
And again, at 318m active parameters @ 4.0 billion tokens (on a different dataset, with a different learning rate):
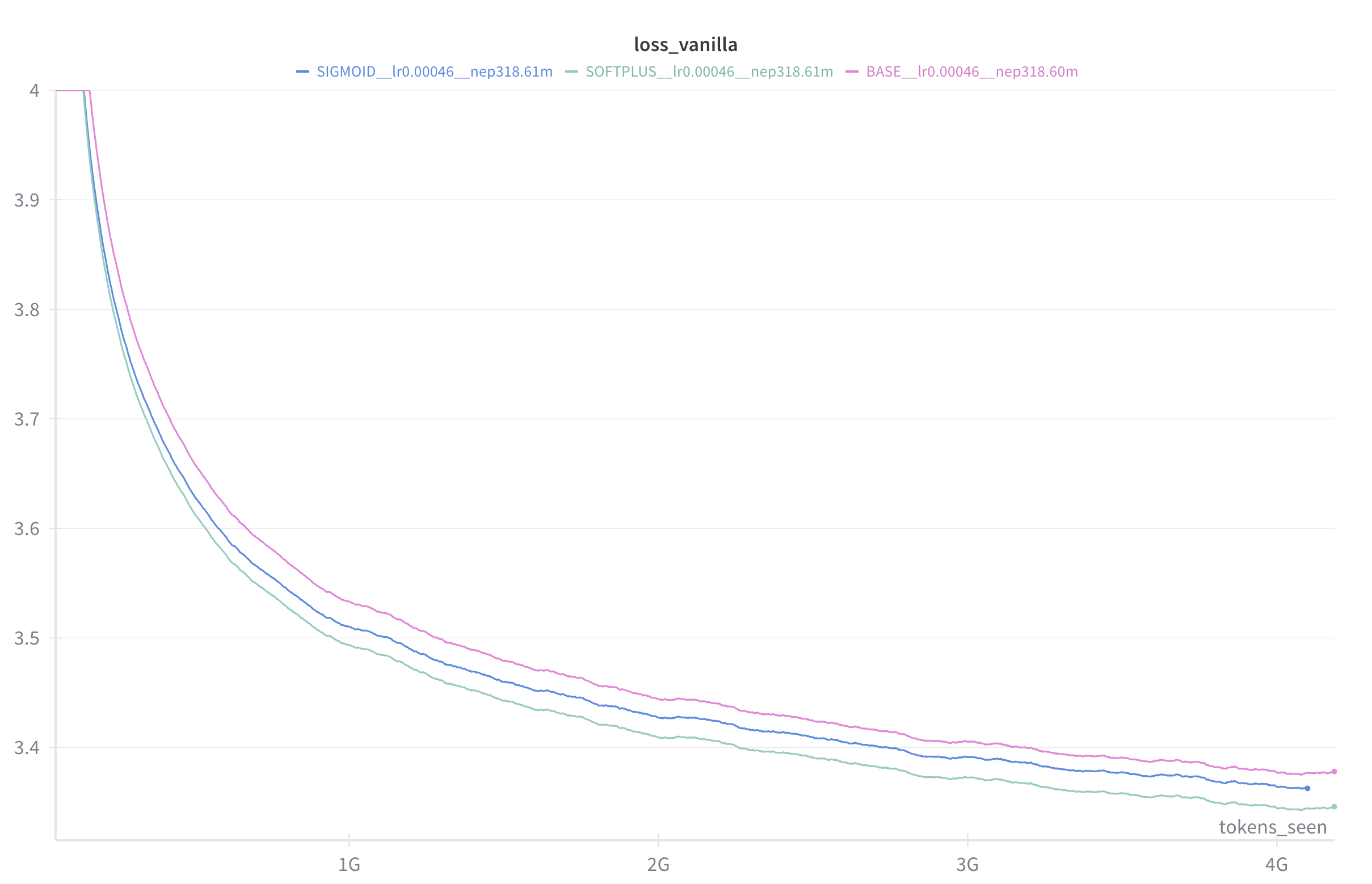
(Both of the above charts are using steps / tokens rather than time for the x-axis, because I'm running on different machines, but by wallclock time the gain remains basically the same.)
Note that the relative size of the gain seems to tend to increase towards the end of the chart.
Softplus Handles Large LR More Gracefully
The last example above uses a learning rate of 0.00046 with a batch size of 48 and a sequence length of 512. This learning rate is already reasonably large. Suppose you double this, to 0.0092?
If you do so, while sigmoid-gated attention works worse (as you would expect), while softplus-gated attention actually performs slightly better!
In the below, blue is sigmoid-gated attention while red is softplus-gated attention. The darker-colored examples have a lower learning rate, while the lighter-colored examples have a learning rate twice as high.
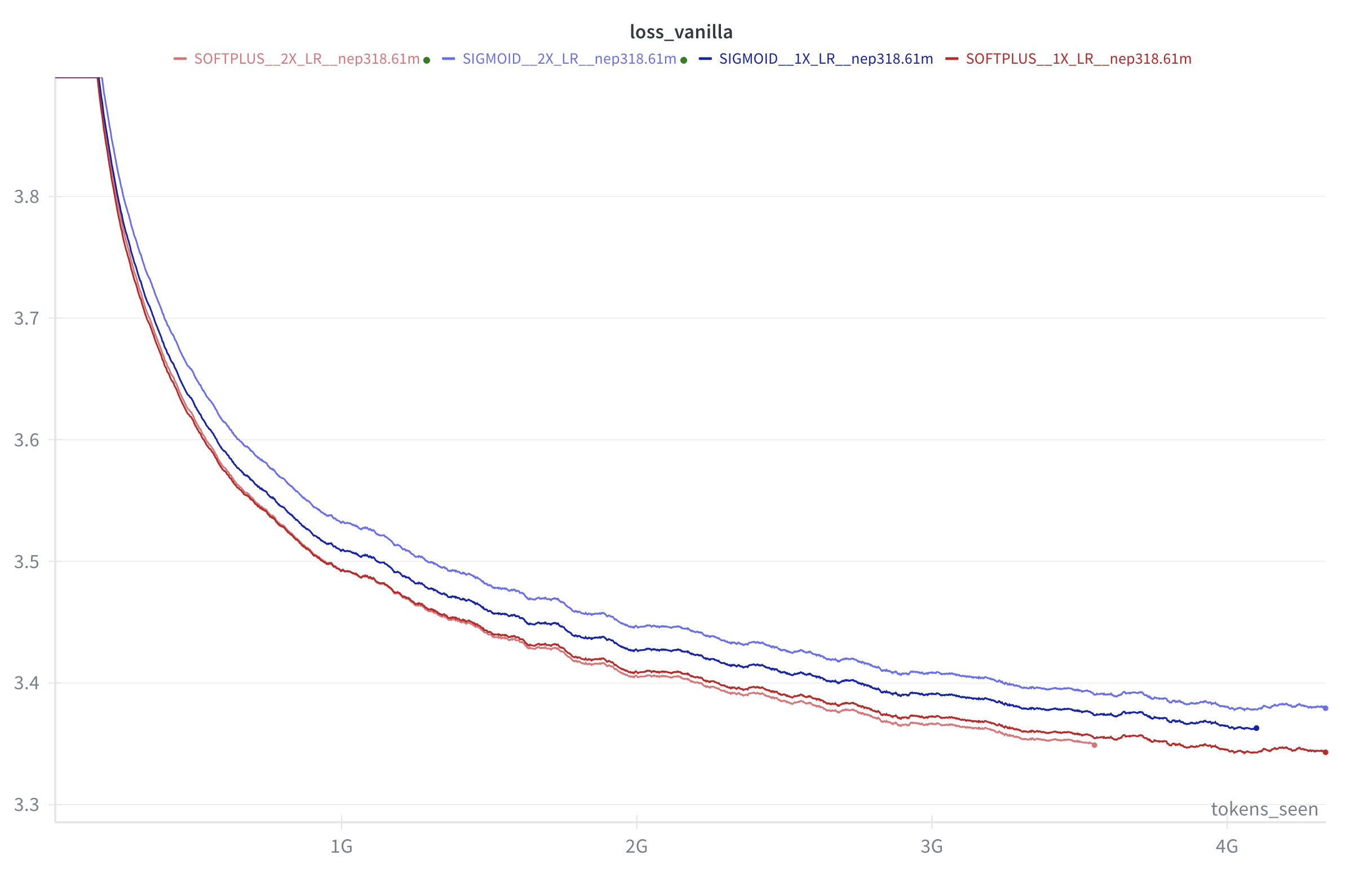
So softplus-gated attention handles a large learning rate much better and more stably, to a degree that's surprising to me.
(If you halve the learning rate, softplus-gated attention remains better than sigmoid, although both do worse overall.)
Head Number Ablations
I was curious if Softmax, Sigmoid, and Standard attention had different optimal attention head sizes / number of heads.
So I varied the size / number of heads from 2 heads with a dimension of 360 per head, to 20 heads with a dimension of 36 per head.
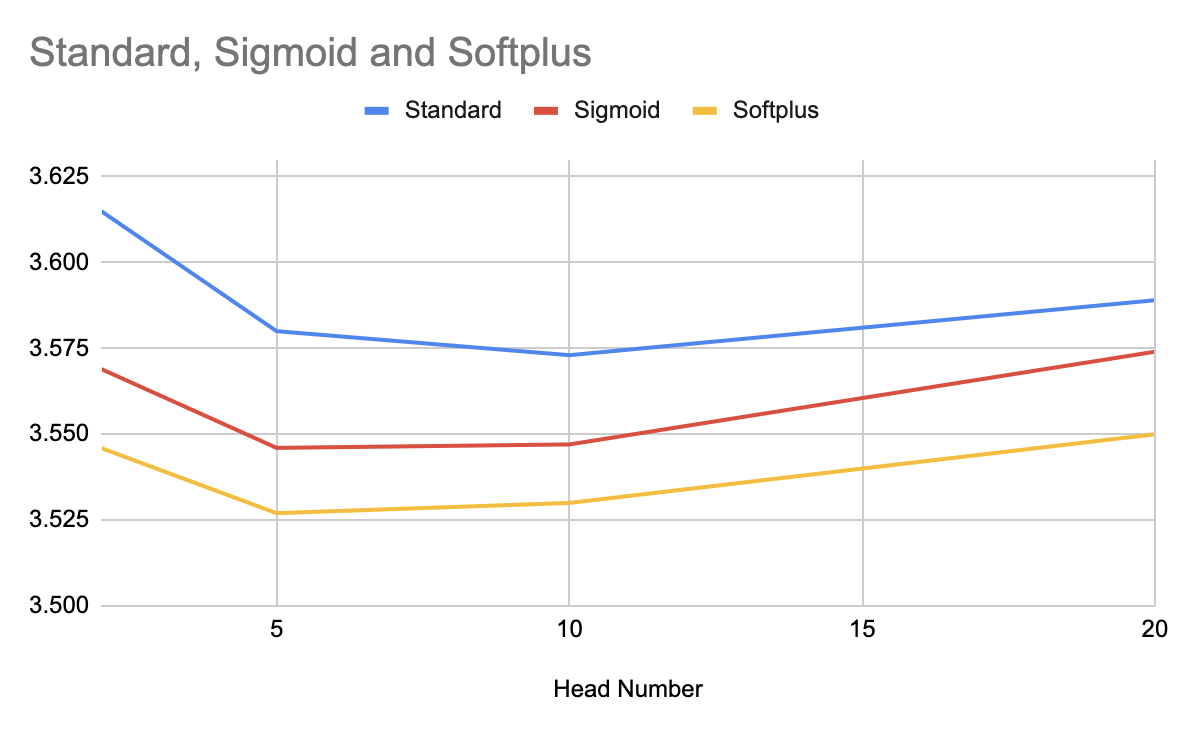
Hard to say, overall. It looks like the gated attention variants might do a bit better with fewer, larger heads. But at least at the scale I'm operating at, the effect wasn't very large. It might be worth bumping up the scale here; this is just on 1.3 billion tokens @ 74m parameters.
Initialization Ablations
I tried a number of ablations for the gates, giving the gates learnable biases (or not), zero-initializing the gates (or not), and zero-initializing the biases (or not).
I actually did a fair bit of work on this at various scales, but then I realized when you widened the networks the difference between initializations seemed to dramatically decrease to just a tiny amount.
Right now, zero-initializing the weights for the gates, and then having a non-zero initialized bias, seems to give pretty good results. But I'm not sure it makes that much difference, particularly at large scales where I just don't have the money to do a good ablation.
Conclusion
Me, or someone, needs to scale this up to like, 1b or 3b to see how well this works. I expect it to keep working though, it's too clean at a small scale and the intuition (always-positive second derivative for softplus; unbounded potential growth for softplus) makes too much sense.